Learning representations with large neural networks has enabled impressive results in AI. Examples of this progress can be seen in computer vision, natural language processing, and audio generation. One area that has yet to see similar progress is robotics. A major reason for this is that robots are typically deployed in real-world environments, where the data distribution is highly variable and often unknown, and data collection is expensive.
Large-Scale Visual Pre-training
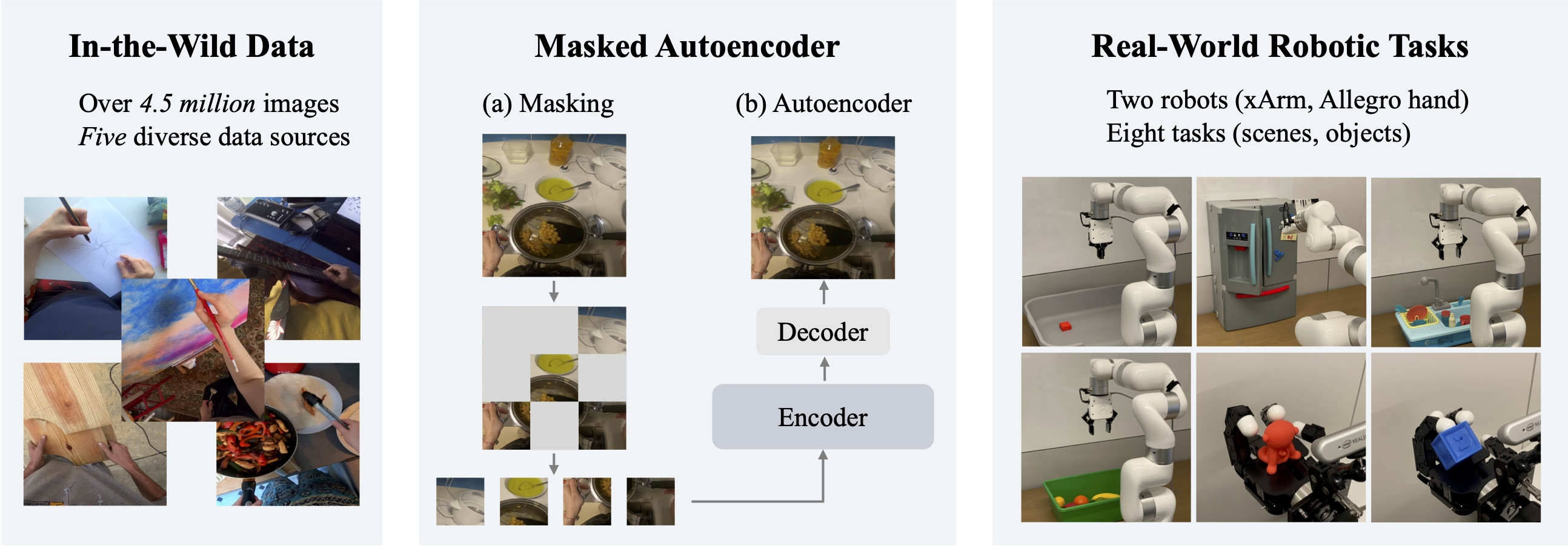
Masked visual pre-training on in-the-wild images for real-world robotic tasks
The Internet contains a wealth of observational data, and a large fraction of the population is now equipped with portable devices that can capture images and videos.
These images and videos cover a wide range of scenes, objects, and activities, and are often captured in the wild.
Inspired by this, we first compile a massive collection of 4.5 million images from ImageNet, Epic Kitchens, Something Something,
100 Days of Hands, and Ego4D datasets.
We use the collected data for learning visual representations with self-supervision.
The core of our approach is the masked autoencoder (MAE).
MAE masks out random patches in an image and reconstructs the missing content with a vision transformer (ViT).
The hope is that, by learning to predict the missing content in real-world images,
the model will learn useful properties of the visual world that will enable it to learn to perform real-world robotic tasks.
One Vision Encoder for All Tasks
After learning the visual representations, we freeze the encoder and pass the representations into a learnable control module. Thanks to this design, we can learn to perform a wide range of real-world robotic tasks using a single vision encoder with only 20 to 80 expert demonstrations and different embodiments (robot arms and robot hands).
The same vision encoder is used for all downstream robotic tasks and embodiments
Enables Solving Various Robotic Tasks
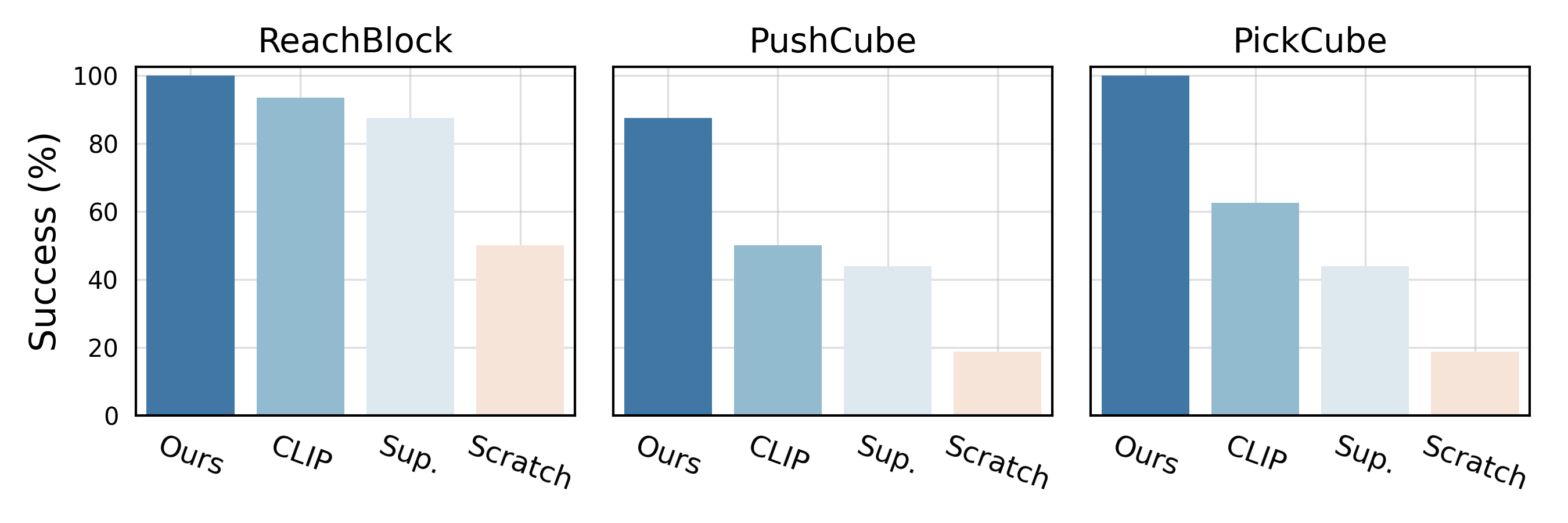
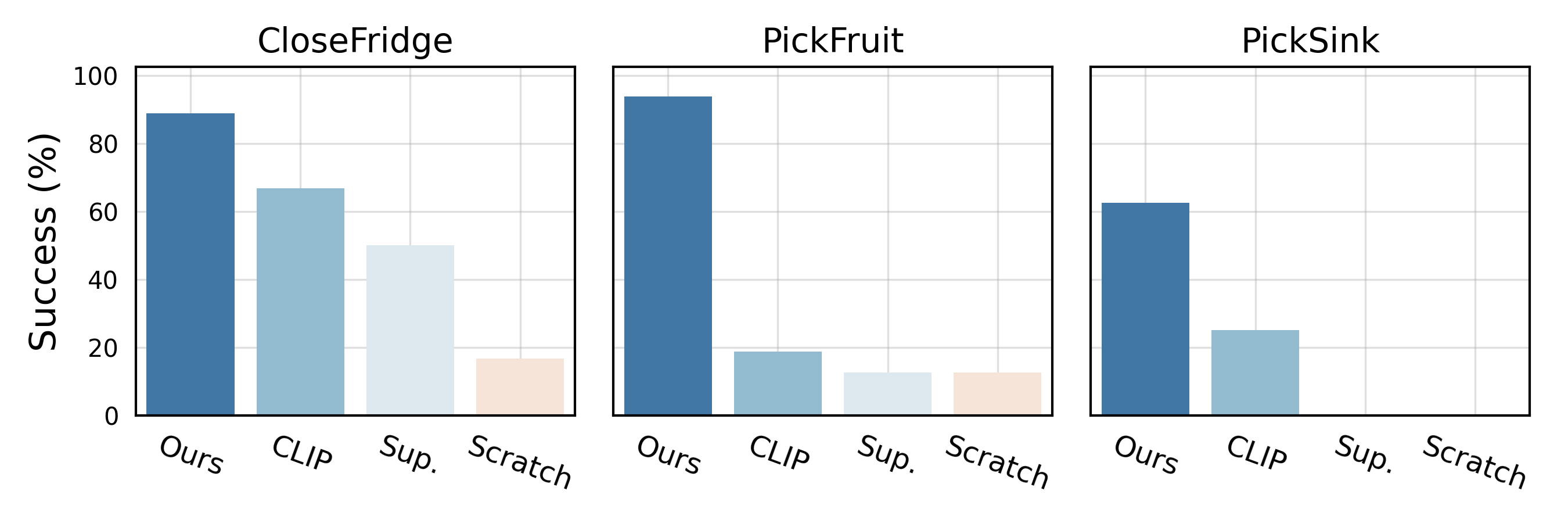
We consider six different tasks for the 7-DoF xArm robot: basic motor control tasks and visually complex tasks. The first category includes tasks that require the robot to perform simple and basic motor control actions, such as reaching a red block, pushing a wooden cube, and picking a yellow cube. The second category involves visually diverse scenes and objects, such as closing a fridge door (scene context), picking eight types of fruits (different objects), and picking a detergent bottle from a sink (object in context). Since our approach learns visual representations from real-world images, it can solve robotic tasks that involve interaction with everyday objects.
The control policies predict joint angles from pixels and make no assumptions about the action space
(for example, by design we do not use the end-effector information for learning).
Therefore, the approach can be directly applied on a multi-finger Allegro hand.
We first consider a reaching task where the goal is to reach the top of an object with the tip of the index finger.
The position of the object is randomized across the palm of the hand.
We evaluate the trained policy on 8 seen objects as well as 45 unseen objects, shown in the following videos.
Reaching an object using the Allegro hand's index finger (seen objects in the first row, unseen for the rest)
Next, we try a cube flipping task in which the goal is to flip a rubber cube that is placed in the palm. The position of the cube is randomized across the palm. Thus, the policy must rely on visual cues to accomplish the task.
Flipping a rubber cube randomly placed on the Allegro hand's palm
Outperforms Standard Vision Encoders
We compare our approach to a set of state-of-the-art vision backbones: CLIP trained on 400M text-image pairs, supervised model trained on ImageNet, and a model trained from scratch with in-domain demonstration data. For fair comparisons, all methods use encoders of the same size. We empirically observe that the CLIP encoder performs the best among the baselines, and the ranking order is consistent across the tasks. Our approach outperforms the baselines by a considerable margin. As the tasks become more complex (for example, pick sink), the gap between our approach and the baselines increases.
Comparison to baseline vision encoders on basic tasks (top) and complex tasks (bottom)
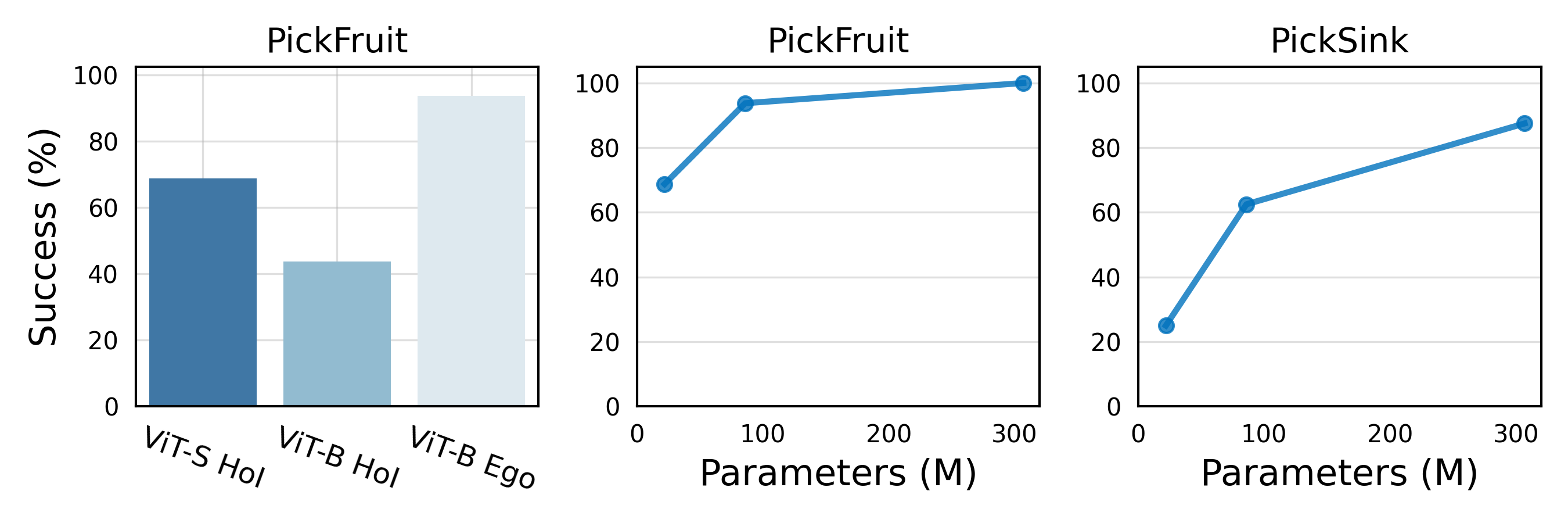
Scales with Data and Model Size
Importantly, our visual pre-training approach uses a self-supervised objective that makes few
assumptions about the data distribution, and does not rely on human-designed pretext tasks such as data augmentations.
Therefore, the framework is well-suited for pre-training from a massive collection of unlabeled and in-the-wild visual data.
Here we study scaling model and data size.
We first increase the model capacity. On the left of the figure,
we see that increasing the model size (~4.5x) from ViT-S to ViT-B,
while keeping the data size fixed, does not increase performance and even hurts.
However, if we also scale the data size from HOI to our massive Ego data collection, ViT-B brings considerable gains.
These results suggests that we must scale both the model and the data.
In the middle and the right pannel, we show the performance as a function of model size.
Additionally increasing the model size from the 86M parameter ViT-B to the 307M parameter ViT-L leads to further improvements.
We also observe that the gain is larger for he visually harder task.
To the best of our knowledge, ours is the largest vision model deployed to real robot tasks,
and clearly demonstrates the benefits of scaling visual pre-training for real-world robot learning.
Scaling model and data size
Collecting Demonstrations
xArm.
We use an HTC Vive VR controller (left) to collect demonstrations for the xArm.
The setup includes two external sensors that track the position of the VR controller and estimate its 6-DoF pose.
Given the 6-DoF pose of the controller, we use it to control the end-effector (EE) pose of the robot.
We map the EE pose to the joint angles via inverse kinematics (IK).
We control the gripper open/close state via a button on the controller.
Using this pipeline, the user controls the system in real-time while having direct view of the robot.
While the user is performing the task, we save the camera feed and robot state information as demonstrations.
On average, it takes about one hour to collect 40 demonstrations using this setup.
Allegro hand.
It is generally hard to control a multi-finger hand using a joystick or a VR controller.
We developed a new approach based on the Meta Quest 2 device (right).
We use the hand tracking provided by the Quest 2 to obtain the 3D keypoints of the human hand.
We then map the human keypoints to the Allegro hand joint angles using IK.
The system runs in real-time and records demonstrations
while the human is controlling the robot to complete the desired task.
Collecting xArm demonstrations via the HTC Vive VR controller
Collecting Allegro Hand demonstrations via a Meta Quest 2
Failure Cases
The system is not perfect and can fail in a variety of ways. Here are some examples of failure cases. For the xArm, failure happens when the robot's approaching trajectory is not sufficiently precise to reach the grasping location, resulting in the robot's gripper colliding with the object (the first and the third video below); or when the robot closes its gripper too early, resulting in the object falling out of the gripper (the second and the fourth video below).
Inprecise approaching trajectory
Premature closing of gripper
Collision with object
Premature closing of gripper
We generally observed four types of failure cases for the Allegro hand: (1) The index finger refuses to approach the object at all. (2) The index finger reaches the object but does not stop in time. (3) The ring finger gets stuck after colliding with the middle finger. (4) The ring finger gets stuck after colliding with the object.
The index finger refuses to approach the object at all
The index finger reaches the object but does not stop in time
The ring finger gets stuck after colliding with the middle finger
The ring finger gets stuck after colliding with the object
BibTeX
@article{Radosavovic2022,
title={Real-World Robot Learning with Masked Visual Pre-training},
author={Ilija Radosavovic and Tete Xiao and Stephen James and Pieter Abbeel and Jitendra Malik and Trevor Darrell},
year={2022},
journal={CoRL}
}