
| Google Scholar | Github |
|
I co-founded Prompt AI and am currently serving as its CEO in the San Francisco Bay Area. See more information from our press release. I received a Ph.D. degree from UC Berkeley, advised by Prof. Trevor Darrell. My research interests lie in the fields of computer vision, robotics and machine learning, with a focus on learning scalable representations via deep learning. I was also affiliated with Facebook AI Research (FAIR), where I was fortunate to work with Piotr Dollár and Ross Girshick. Prior to UC Berkeley, I received a B.S. degree in Intelligence Science, summa cum laude, from Peking University (PKU) in 2019. |
|
|
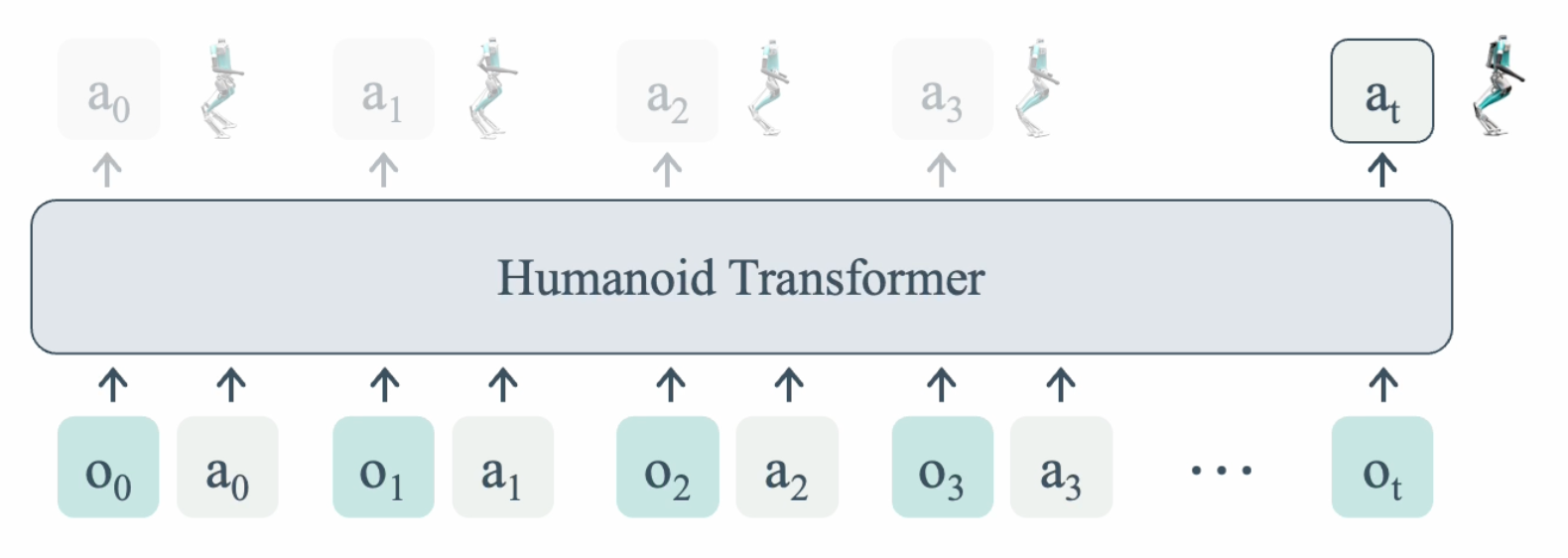
We present a sim-to-real learning-based approach for real-world humanoid locomotion. To the best of our knowledge, this is the first demonstration of a fully learning-based method for real-world full-sized humanoid locomotion. |
|
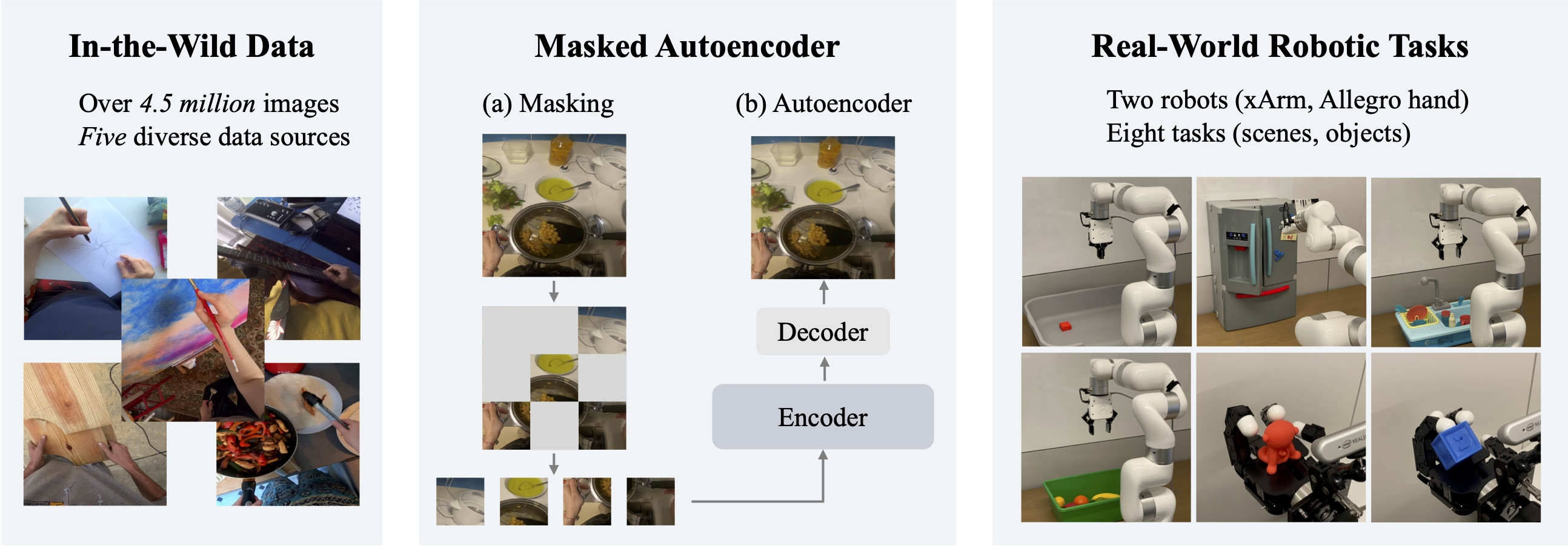
We explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. We train a big vision transformer on a massive collection of images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning. |
|
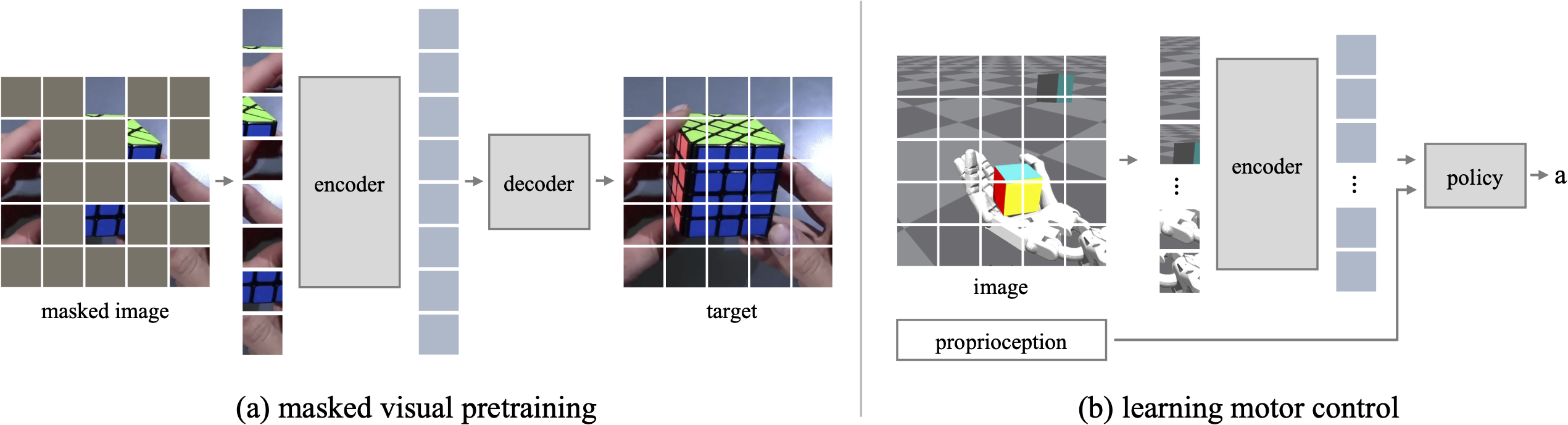
We show that self-supervised visual pre-training from real-world images is effective for learning motor control tasks from pixels. |

|
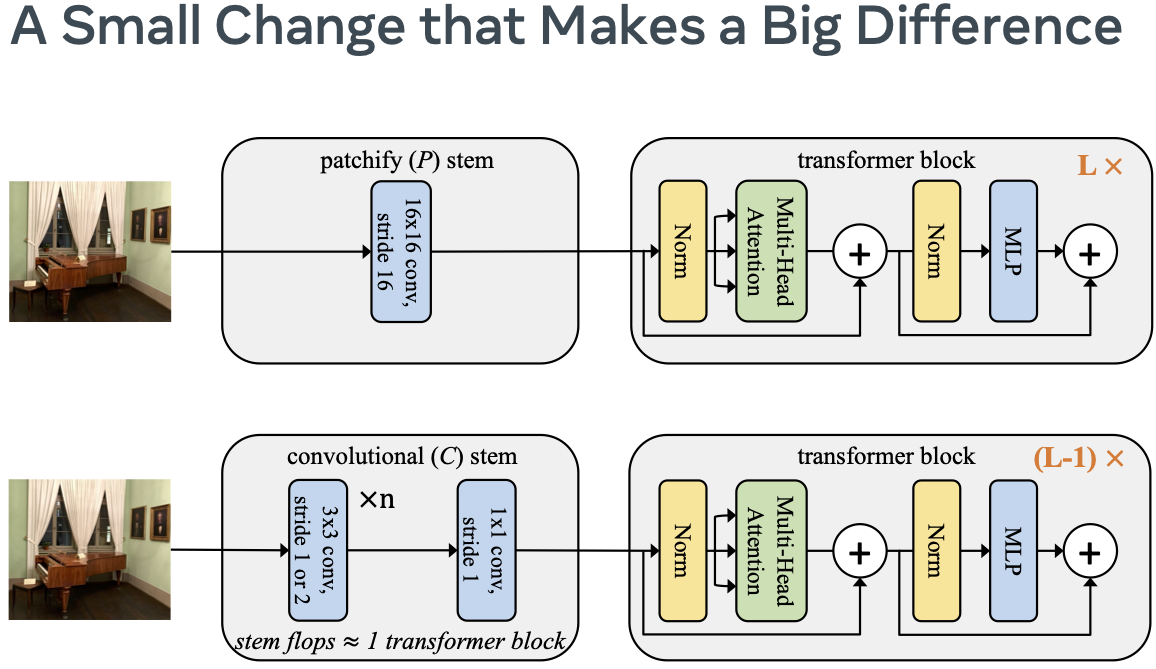
We analyze the substandard optimization behavior of ViT and propose a simple fix that dramatically increases optimization stability and also improves peak performance. |
|
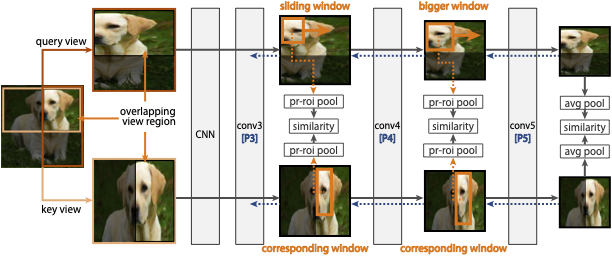
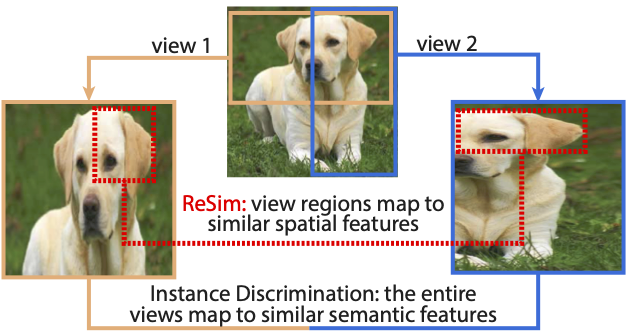
An approach to self-supervised representation learning for localization-based tasks such as object detection and segmentation. |
|
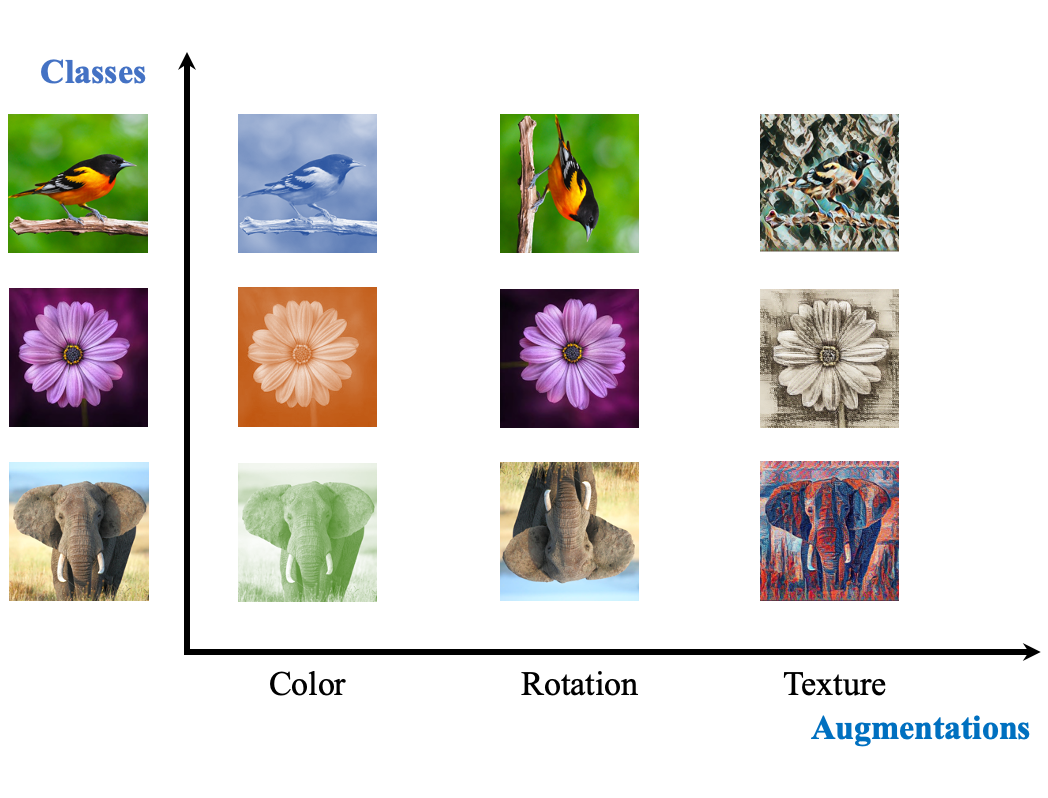
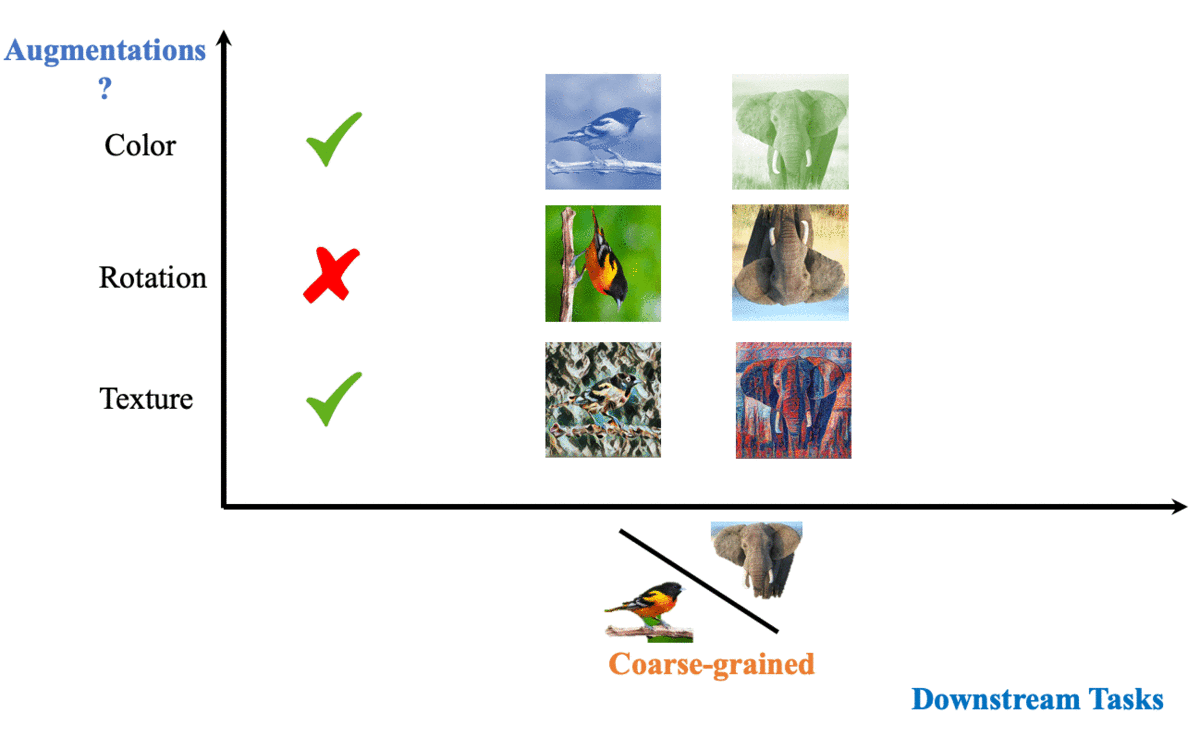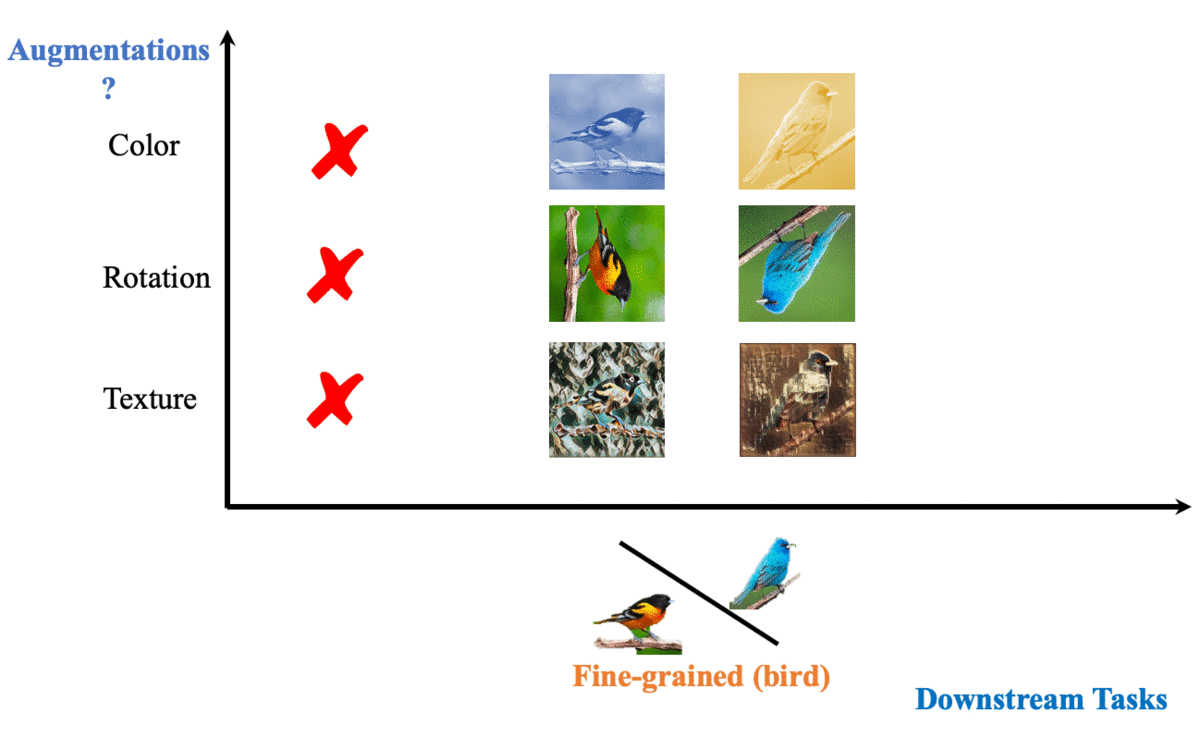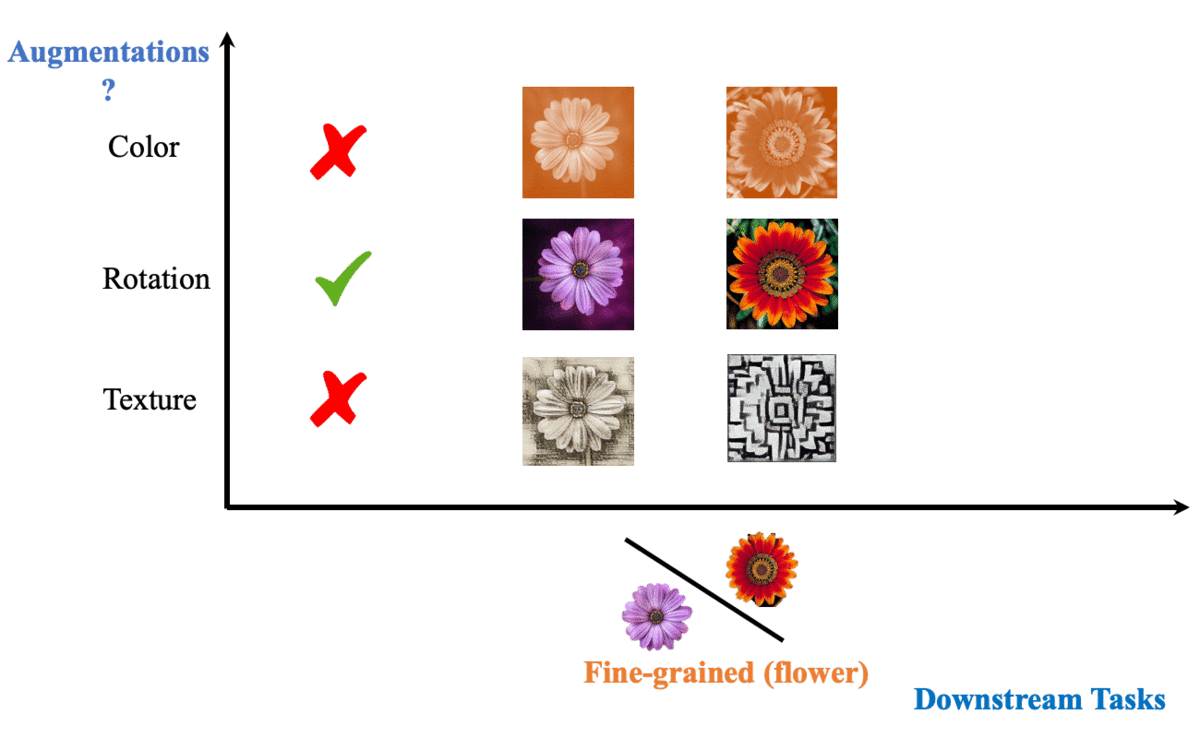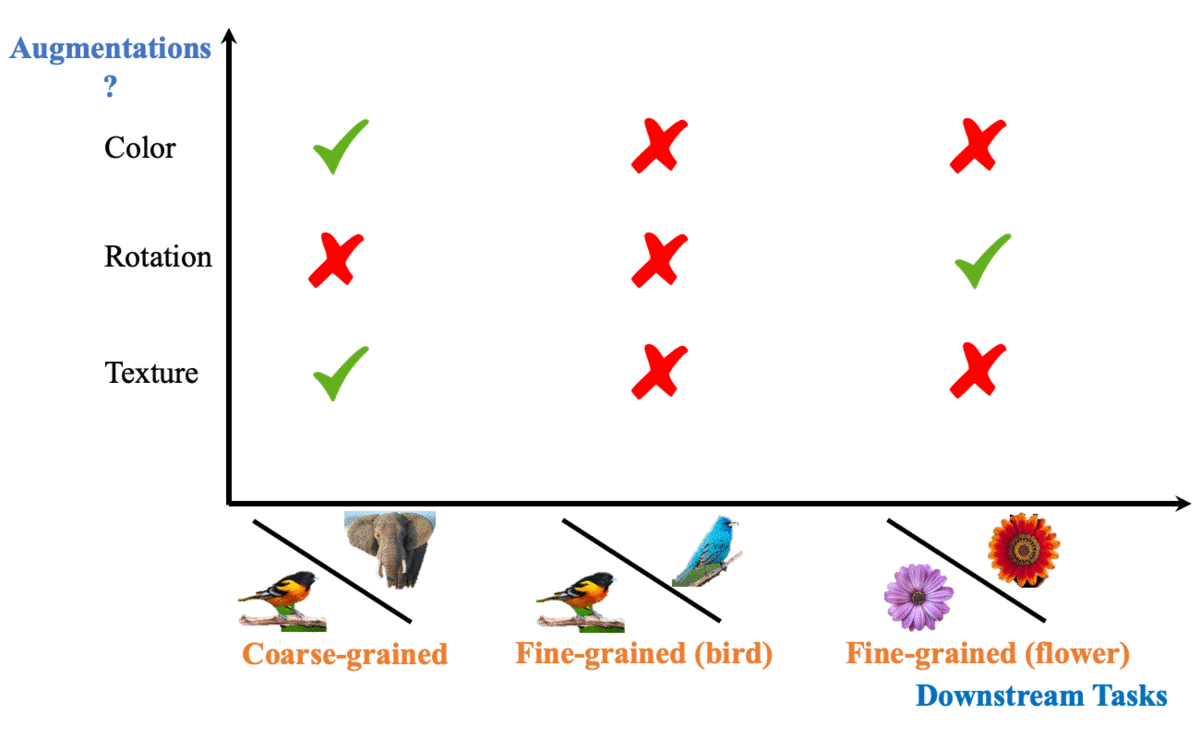
To contrast, or not to contrast, that is the question. |
|
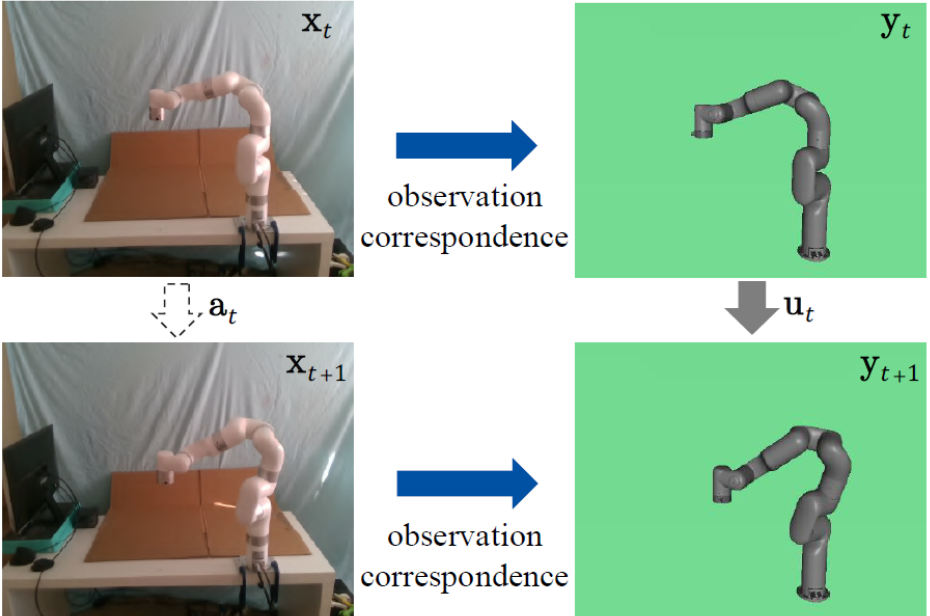
Learning correspondence across domains differing in representation (vision vs. internal state), physics parameters, and morphology. |

|
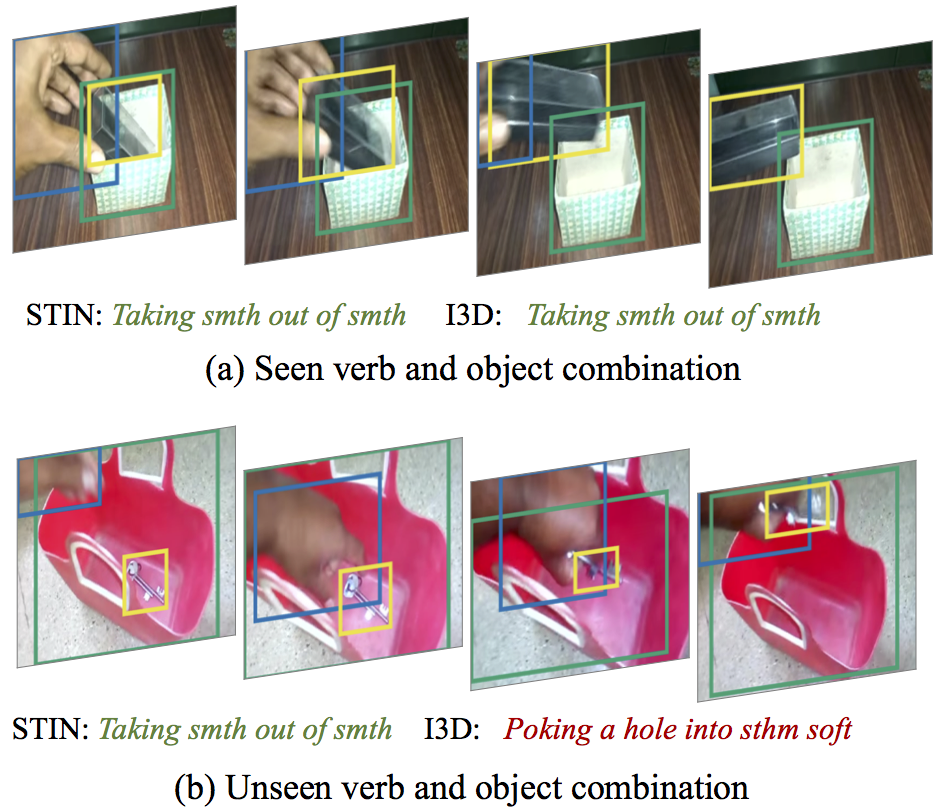
Using Spatial-Temporal Interaction Networks (STIN) for compositional action recognition plus a new annotated dataset Something-else. |

|
Dual Attention Network model reasoning about human-object interactions. |


|
ADE20K dataset with comprehensive analysis and applications. |


|
Pyramid-like parser UPerNet used for Unified Perceptual Parsing task to recognize as many visual concepts as possible from a given image. |



|
Dissecting object localization through IouNet and Precise RoI Pooling. |

|
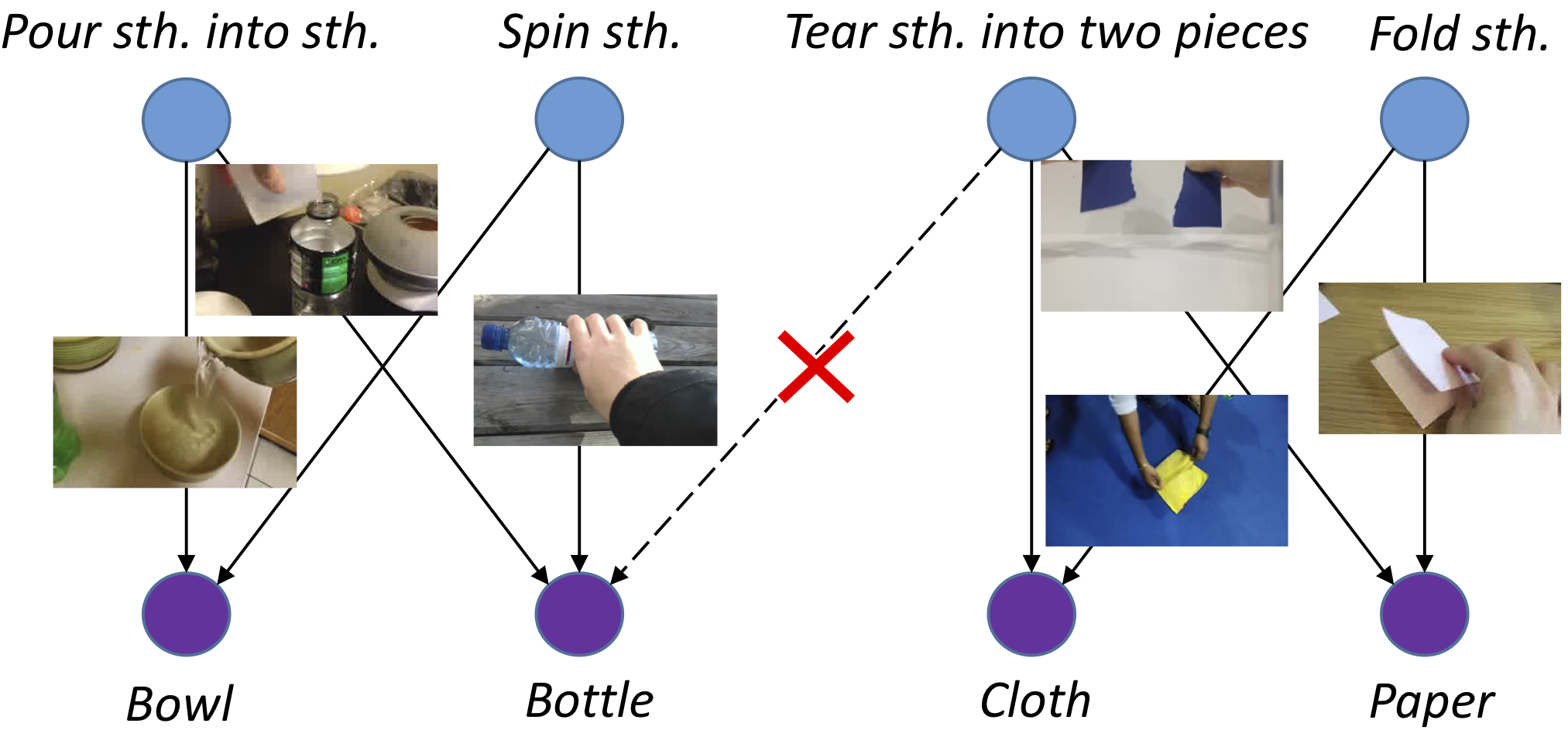
Constructing constrastive image-caption pairs for learning visually-grounded semantics. |

|
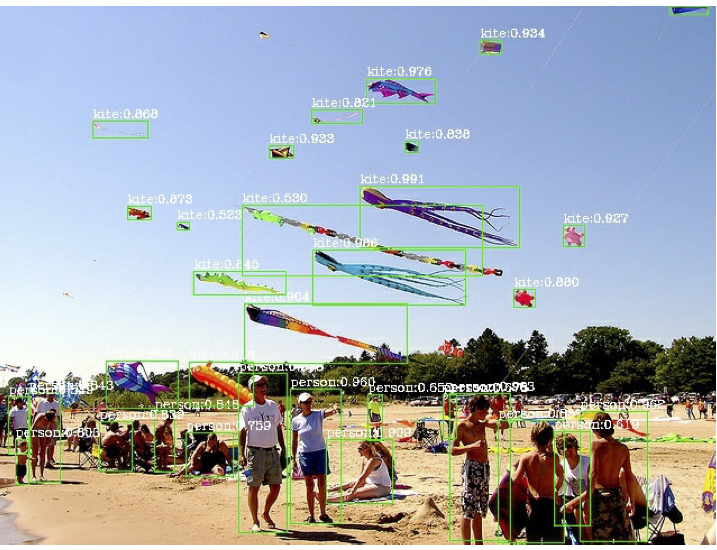
Scaling-up training of object detectors; winner of MSCOCO Challenge 2017. |
|
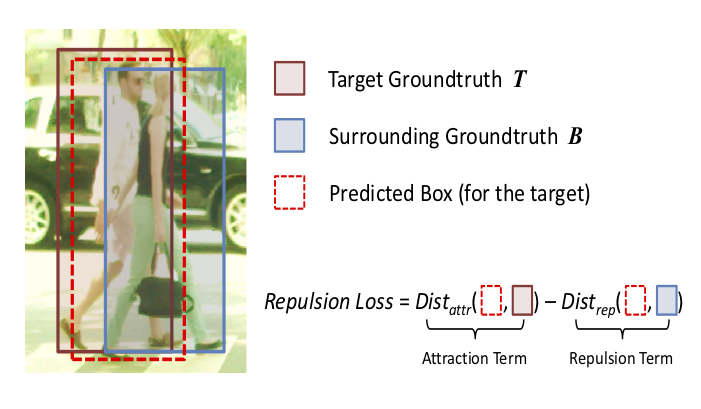
The pedestrian detector that works better for crowd occlusion. |
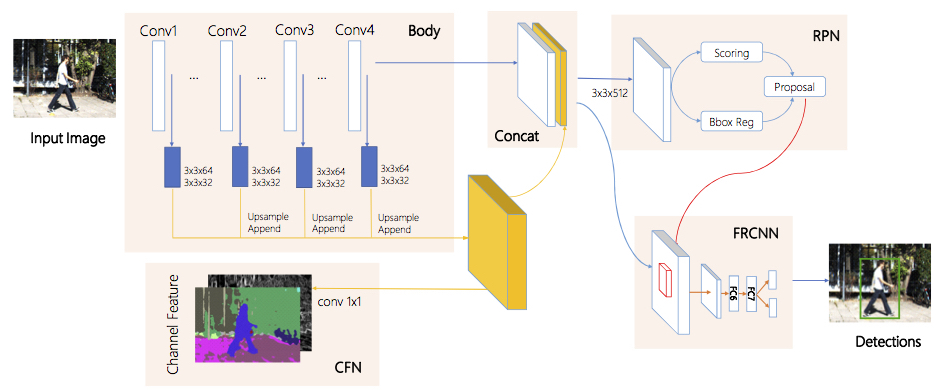
|
|
|
 |
Teaching Faculty, Practice in Programming (17-18 spring)
Teaching Faculty, Artificial Intelligence and Computer Vision (18-19 spring) |
Berkeley Artificial Intelligence Research Lab |
Website design: ✩ ✩ |